
티스토리 뷰
이 포스트는 「"Computer Organization and Design -The hardware / software interface"
by Patterson and Hennessy, 5th edition, 2013.」을 참고하여 작성했습니다.
Power Trends
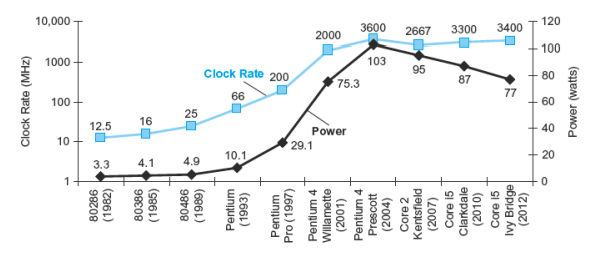
위 그래프는 Power와 Clock Rate를 나타낸 그래프이다.
2001년까지의 그래프를 보면 Power가 증가할 때 Clock Rate 역시 증가했던 것을 확인할 수 있다.
그러나 2004년에 Clock Rate가 한계치에 도달했고, 그때의 Power역시 가장 높았다.
2004년 이후로는 Clock Rate를 더 이상 올리는것이 한계점에 다다랐고 그 이후에는 Power를 줄이는 것이 더 중요하게 되었다. Power는 아래와 같이 계산할 수 있다.

Frequency는 Clock rate를 말하므로 Power는 Frequency에 비례한다.
성능을 향상시키기 위해서는 Frequency는 유지해야 하며 Capacitive load와 Voltage의 값을 감소시켜야 한다.
Voltage를 감소하는 방법은 예를 들어 5V에 1을 나타내고 0V에 0을 나타냈다면 5V에 확인했던 것을 최대한 0V에 가깝게 낮출수록 Voltage는 감소하게 되고 Power 역시 감소하게 된다.
그러나 Voltage를 줄이는것도 거의 한계치에 다다랐다. 왜냐면 일정 기준 이상 Voltage를 줄이게 되면 실제 시스템은 fluctuate 하므로 1과 0의 혼선이 발생하기 때문이다.
예를 들어보자. 새로운 프로세서를 업그레이드 하려고 한다.
이전 프로세서의 capacitive load의 85%을 사용하며 voltage와 frequency를 15% 감소시킨다.
위의 식을 통하여 아래와 같은 식을 세울 수 있다.

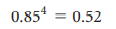
이 식을 통해 새로운 프로세서는 이전 프로세서의 50%파워를 사용함을 알 수 있다.
그러나 이런식으로 Power를 줄이는 것은 한계가 있다. 줄일 수 있는 volatge에는 한계가 있으며 heat 역시 줄일 수 있는 한계가 존재한다.
그렇다면 우리는 어떻게 성능을 향상시킬 수 있을까?

위 그래프는 시대 별 Uniprocessor의 성능을 나타낸다.
1986년부터 2002년까지 해 마다해마다 52%의 상승이 있었지만 2003년 이후로는 해마다 22% 상승에 그쳤다.
이처럼 시간이 지날수록 Uniprocessor의 성능향상에는 반드시 한계가 존재한다.
이러한 문제점을 극복하고 프로세서의 성능향상을 위해 서로 다른 프로세서들을 연결하는 멀티 프로세서(Multiprocessors) 개념이 등장했다. 듀얼코어, 쿼드코어 등이 이에 해당한다.
멀티 프로세서는 Parallel programming을 요구한다. 우리의 프로그램을 각각의 프로세서에 맞게 쪼개 주는 magic compiler는 존재하지 않는다. 따라서 Parallel Programming을 통하여 HW가 multiple instruction을 수행하게 해야 한다.
최적화, 동기화, Load balancing 등을 고려하는 것은 굉장히 어려운 문제이다.
일반적으로는 Parallelism이 불필요하다. 여러 개의 프로그램이 있다면 프로그램 하나씩을 하나의 프로세서에 할당하면 되기 때문이다. 그러나 인공지능, 머신러닝과 같은 하나로 이루어진 거대한 프로그램은 Parallelism을 이용한 처리가 필요하다.
SPEC Benchmark
CPU 제조사들은 자신의 CPU를 판매하기 위해 자신의 CPU 성능을 자랑한다.
이때 대부분의 CPU 제조사는 다른 CPU와 비교하여 본인 CPU의 성능이 우수함을 자랑할 것이다.
그러나 CPU 제조사들은 타 CPU와 성능 비교를 할 때 자신의 CPU에 유리한 프로그램을 만들어 비교하므로 공정한 평가를 보장할 수 없다. 이를 위해 등장한 것이 SPEC Benchmark이다.
SPEC Benchmark는 성능을 측정하기 위한 프로그램들의 Set으로 이루어져 있다.
Standard Performance Evaluation Corp의 약자이며 CPU, I/O, Web 등의 성능평가를 한다.
CPU의 성능을 측정할 땐 I/O를 무시하며 오직 CPU 성능만을 측정한다.
Fallacy : Lowe Power at Idel
많은 사람들이 Power와 CPU의 성능이 비례관계라고 생각한다. 그러나 이는 잘못된 생각이다.

위 그림은 i7의 벤치마크 성능이다.
10% Load를 하는 데에도 47%의 Power가 필요함을 알 수 있다. 이 처럼 Power와 Load는 비례하는 관계가 아니다.
Power는 실제로 CPU에 의한 영향보다는 air condition, heat등에 의한 제약을 더 많이 받는다.
파워의 cost가 더 클까? heat에 의한 cost가 더 클까?
실제로는 CPU Power의 비용보다 Power로 인한 heat을 조절하기 위한 air condition 비용이 더 비싸다.
실제로 구글 데이터센터에서도 항상 100%의 Power와 100%의 Load가 일어나는 것이 아니다.
도로가 항상 자동차로 꽉 차 있지 않듯이 트래픽에 따라 power와 load는 달라지게 된다.
많은 개발자들이 실제로는 Power와 Load가 비례하여 사용되도록 개발 중이다.
MIPS as a Performance Metric
MIPS : Millions of Instructions Per Second를 의미한다. 우리가 강의 초반에 봤던 MIPS(ISA)랑은 다른 개념이다.
먼저 MIPS만으로 성능 판단이 불가능하다는 점을 기억하자. 우리는 MIPS를 계산함으로 1초에 몇 번의 연산을 할 수 있는지는 알 수 있지만 1 연산에 걸리는 시간은 알지 못한다.

MIPS는 컴퓨터 간 ISA의 차이와 연산의 시간 복잡도를 고려하지 않는다.
MIPS에 대한 예시를 살펴보자.

A컴퓨터와 B컴퓨터 중
1. 어떤 컴퓨터의 MIPS rating이 높을까?
2. 어떤 컴퓨터가 빠를까?
위 MIPS를 계산하는 공식을 통하여 A와 B의 MIPS를 구하게 되면 A는 4000 MIPS, B는 약 3800 MIPS임을 알 수 있다.
따라서 A의 MIPS rating이 더 높은 것을 알 수 있고, 우리는 I.C와 CPI와 Clock rate를 알기에 CPU Time 역시 계산할 수 있다. 계산하게 되면 B컴퓨터가 더 빠른 것을 알 수 있다.
RISC vs CISC
RISC는 Reduced Instruction Set Computing을 의미한다. MIPS, ARM, PowerPC 등이 이에 해당한다.
CISC는 Complex Instruction Set Computing을 의미한다. Intel 8080, x86 아키텍처 등이 이에 해당한다.
RISC는 간단한 연산을 생각하면 된다. 간단한 연산으로 이루어져 있으며 간단한 HW로 이루어져 있다.
CISC는 복잡한 연산이다. 더 복잡한 연산을 수행하게 한다. CISC의 목적은 실행되는 연산의 개수를 줄이는 것에 있다.
그러나 CPI가 높아지거나, Cycle time이 느려진다는 단점이 있다.
예를 들어 RISC를 c=a+b라는 연산이라고 한다면 CISC는 d=a+b+c라는 연산이 될 것이다.
우리가 만약 z=x+y+w라는 명령을 컴파일하게 된다면 RISC는 t=x+y, z=t+w라는 두 개의 연산으로 나누어 계산할 것이며, CISC는 z=x+y+w라는 연산을 한 번에 수행할 것이다.
그렇다면 우리는 연산의 개수가 적은 CISC가 더 빠르다고 생각할 수 있을까?
답은 X다. CISC의 연산의 개수가 적은 건 맞지만 빠른다고는 확신할 수 없다.
예를 들어 c=a+b라는 연산의 CPI가 1이고 d=a+b+c라는 연산의 CPI가 5라 해보자.
z=x+y+w를 컴파일하였을 때 RISC의 사이클은 2이고 CISC의 사이클은 5이므로 실제로는 CISC의 시간이 더 오래 걸림을 알 수 있다. 이처럼 우리는 연산의 개수만으로는 성능 비교가 불가하다.
실제로는 대부분 CISC구조에서 RISC구조로 바뀌고 있는 추세이다.
RISC는 simple ISA를 사용하므로 파이프라인 구현이 가능하게 한다는 등의 장점이 있다.
또 빠른 실행을 위해서는 simple instruction이 반드시 필요하다.
CISC는 RISC에 비해 3/4 instruction을 사용하지만 CPI는 6배가 되며 이로 인해 속도 차이는 RISC가 CISC보다 4배 정도 빠르다. 오늘날 99%의 프로세서는 RISC를 사용하고 있다.
프로세서의 성능 향상은 점점 한계치에 다다르고 있다. 이제는 Parallel programming을 통해 성능 향상을 꾀해야 한다.
또한 특정 도메인에서의 Architecture를 통해 성능 향상을 불러올 수 있다. 머신러닝을 수행할 때 GPU를 이용하는 것처럼 범용으로는 사용할 수 없지만 특정 Domain에선 CPU보다 높은 성능을 보여줄 수 있다.
Lecture Note #4에서 계속..
'Lecture Note > Computer Architecture' 카테고리의 다른 글
| 컴퓨터 구조(CA) Lecture Note #6 (0) | 2020.09.28 |
|---|---|
| 컴퓨터 구조(CA) Lecture Note #5 (0) | 2020.09.26 |
| 컴퓨터 구조(CA) Lecture Note #4 (0) | 2020.09.19 |
| 컴퓨터 구조(CA) Lecture Note #2 (0) | 2020.09.12 |
| 컴퓨터 구조(CA) Lecture Note #1 (0) | 2020.09.04 |
- Total
- Today
- Yesterday
- 컴퓨터 통신
- 중앙대학교
- java
- 그리디
- nestjs
- ReactNative
- 컴퓨터 구조
- 구현
- 벨만포드
- node.js
- nest.js
- boj
- typeORM
- 백준
- 자바
- 재귀
- 그래프
- 자바스크립트
- 스레드
- nodeJS
- Computer Architecture
- 동적계획법
- 백트래킹
- 시뮬레이션
- 투포인터
- 예외처리
- 세그먼트 트리
- dfs
- BFS
- 알고리즘
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |