
티스토리 뷰
이 포스트는 「"Computer Organization and Design -The hardware / software interface"
by Patterson and Hennessy, 5th edition, 2013.」을 참고하여 작성했습니다.
String copy Example

문자열을 복사하는 strcpy함수가 MIPS 코드로 어떻게 번역되는지 알아보자.
x와 y의 주소는 각각 $a0,$a1에 저장되어 있으며 i는 $s0에 저장되어 있다.

먼저 addi연산을 통해 스택 포인터를 이동시켜 스택을 사용할 공간을 확보했다.
그 후 i의 값을 스택에 저장하고 i=0을 수행한다.
그 후 $t1에 $s0과 $a1을 더한 값을 저장한다. 이는 y+i의 주소를 의미한다. 그 후에 $t2에 y [i]의 값을 저장한다.
그다음 $t3에 마찬가지로 x+i의 주소를 저장한 후에 sb를 통해 x [i]=y [i]의 연산을 수행한다.
그 후에 beq연산을 통해 x [i]의 값이 0인지 확인하고 0이라면 L2로 점프하여 다시 $s0의 값을 불러오고 스택을 pop 하여 return 하는 구조이다.
32-bit constants
대부분의 상수들은 작기에 I-format의 constant필드를 통해 해결이 가능하다. 하지만 가끔씩 32-bit의 상수값을 이용해야 할 때가 있다. 그럴 때는 어떤 방법을 사용해야 할까? I-format으로는 32-bit의 상수를 다 담을 수 없다.
이때 사용하는 방법은 $s0레지스터를 이용하는 방법이다. 레지스터는 32bit의 크기를 가지고 있다.
먼저 lui 연산을 통해 $s0의 왼쪽 16bit을 채워주고(오른쪽 16bit은 0) ori연산을 통해 $s0의 오른쪽 16bit를 채워 총 32bit의 상수가 저장되게 한다.
Branch Addressing
MIPS에는 beq, bne 등 분기 연산이 존재한다. 이는 조건을 판단하여 원하는 주소로 이동하는 명령어이다.
이 명령들에서 분기가 어떻게 이루어지는지 알아보자.
우선, beq, bne연산은 I-format 연산으로 16bit의 Adress를 담을 공간을 가지고 있다.
대부분의 branch연산의 목표 주소는 현재 위치에 가까운 곳에 위치하고 있기 때문에 16bit에서 처리가 가능하다.(if, loops 등)
branch 연산에 사용하는 주소 계산방법은 PC-relative addressing이다.
Target address = PC + offset * 4를 통하여 주소를 설정할 수 있다.
여기서 offset은 16bit에 저장된 address주소를 말한다. 4를 곱해주는 이유는 하나의 연산이 4byte이기 때문이다.
이 방법을 통하여 우리는 +-2^15의 byte를 이동할 수 있다.
따라서 실제로는 (PC+4) + offset * 4 를 통하여 Target address를 설정할 수 있다.
만약 branch연산을 통해 분기하고자 하는 거리가 매우 멀 경우 어셈블러는 자동적으로 코드를 재 작성한다.
예를 들어 beq $s0, $s1, L1 명령에서 L1의 거리가 표현이 불가능한 거리라면
bne $s0, $s1, L2 , j L1 명령을 통하여 명령을 두 개로 나누어 이동을 수행한다. J-format은 어느 거리던 이동할 수 있기 때문이다.
Jump Addressing
jumb연산에는 j와 jal연산이 있다. 이 연산을 통하여 어느 주소든지 이동할 수 있다.
PC와 거리가 멀더라도 text segment를 통하여 이동이 가능하다.
위 명령을 J-format형식에 속한다. J-format은 6bit의 op필드와 26bit의 32bit 필드를 가지고 있다.

Target adress = address * 4를 통하여 설정할 수 있다. 따라서 우리는 총 2^28 byte의 크기에 이동할 수 있다.(2^26에서 *4이므로 <<2와 같음)
하지만 총 32bit의 주소를 이동하기에는 비트가 모자라다. 따라서 이때 필요한 추가적인 4bit를 PC의 TOP 4bit를 이용한다. PC의 첫 4BIT는 메모리의 256BM의 공간을 나타내고 있다. 따라서 4BIT + 28BIT=32BIT의 공간을 이동할 수 있다.
jr연산은 레지스터를 이용하여 jump 하는 것이므로 따로 PC의 BIT를 사용하지 않고 32비트를 표현하는 레지스터를 통하여 바로 점프할 수 있다. 이는 R-format이다.
Addressing mode summary

Decoding Machine Language
머신 코드가 어떻게 번역되는지 알아보자.
00 af8020이라는 hex코드는 어떤 명령을 나타낼까?
먼저 이를 2진수로 변환하여 보면 "0000 0000 1010 1111 1000 0000 0010 0000"이 된다.
먼저 첫 6bit가 op코드를 나타내므로 확인해보면 0으로 이는 R-format명령임을 알 수 있다.
R-format은 op, rs, rt, rd, shamt, funct로 이루어져 있다.
따라서 rs는 5를, rt는 15를, rd는 16을 나타내고 있다. 이를 각각 greencard를 참고하여 확인해보면
rs는 $a레지스터를, rt는 $t레지스터를 rd는 $s레지스터를 나타내고 있음을 알 수 있다.
다음 shamt필드는 shift연산에 필요한 것이므로 0으로 설정되어있고 마지막 funct는 100000으로 32를 나타내고 있다.
따라서 이 op코드와 funct를 이용하여 이 연산이 add연산임을 알 수 있다.(ppt 참고)
따라서 위 머신 코드는 add $s0, $a1, $t7이라는 명령임을 알 수 있다.
어셈블러에는 Pseudo instructions라는 것이 존재한다. 이는 실제 machine명령으로는 존재하지 않지만, 오직 어셈블리 명령에만 존재하는 명령들을 말한다.
move, blt명령어가 그 예시이다. 실제 machine코드에서는 해당 명령어가 존재하지 않는다. 하지만 어셈블리어로는 위 명령어들이 작성이 가능하다. 이것이 가능한 이유는 우리가 move라는 어셈블리 명령을 이용하더라도 실제로 머신 코드를 번역될 때에는 add연산으로 번역되기 때문에 가능하다.
하나의 프로그램이 메모리에 저장되는 과정을 하나의 그림으로 요약하면 아래와 같다.


Sort가 이루어지는 과정을 MIPS코드로 알아보자.
해당 Sort는 bubble sort로 성능이 좋지 못한 코드이다.
일단 Stack을 push 하고 pop 하는 과정은 생략하고, 동작 과정만 보겠다.

먼저 $s2,$s3레지스터에 매개변수인 $a0(v),$a1(n)의 주소를 저장했다.
그 후에 $s0(i)에 0을 넣었다.
첫 번째 for문이 시작된다.
slt연산을 통해 $t0에 i <n의 결과를 저장한다. 만약 $t0이 0이라면 i>=n 일 것이다. 그 후에 바로 beq연산을 통해 $t0이 0일 경우에 즉 첫 번째 for문의 조건이 만족하지 않을 경우에 exit 1로 이동하게 했다.
만약 i>=n이라면 j=i-1을 하여 두 번째 for문이 시작된다.
두 번째 for문에서는 먼저 j<0인지 판단한다. 만약 j>=0이라면 $t0에는 0이 저장되고 그 후 bne연산이므로 0이 아닐경우 exit2로 이동하게 된다. 정리해보면 j>=0이 아니라면 exit2로 이동하게 된다.
그 후 두 번째 for문 실제적으로 sort를 수행하게 된다. 먼저 sll을 이용하여 주소값을 가리키게 한다. 그 후에 해당 값을 $t3에 load한후에 j+1의 값을 $t4에 넣고 $t3과 $t4의 크기를 비교한다. 만약 $t4>=$t3이라면 swap이 발생하지 않고 두번째 for문이 종료하게 된다. 만약 $t4<$t3이라면 $a0,$a1에 값을 바꿔준후 swap기능을 수행한다. 그 후에 j를 -1하여 다시 두번째 for이 반복하게 된다.

실제 Stack의 push와 pop과정까지 고려하면 위와 같은 형태를 띨 것이다.
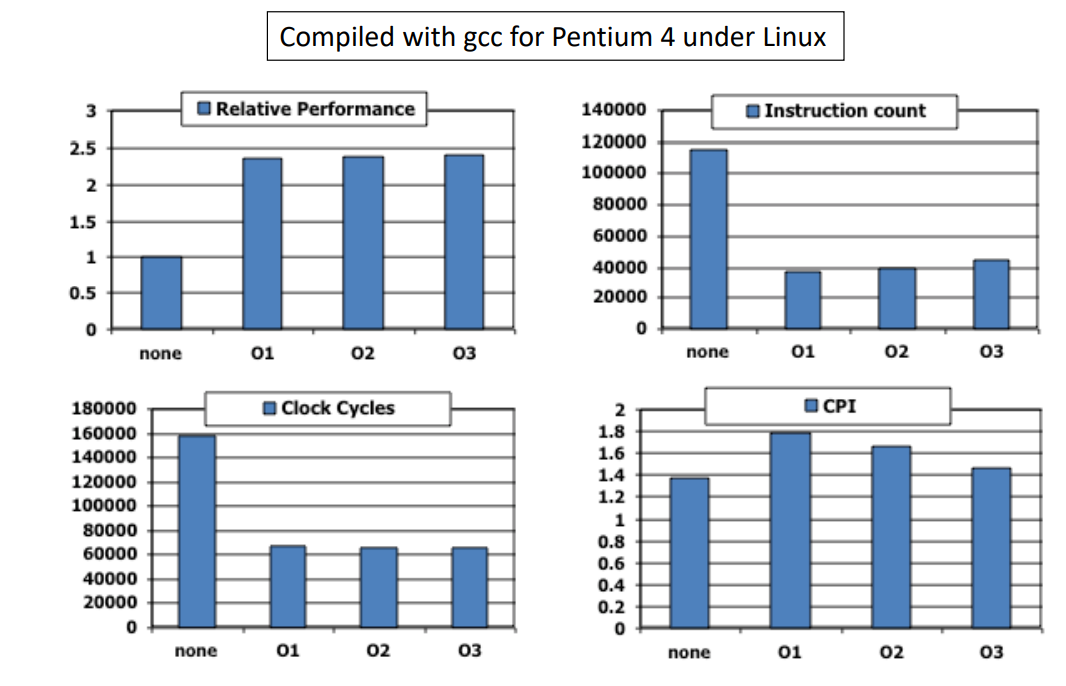
Effect of Compiler Optimization
Effect of Language and algorithm

ARM vs MIPS Similarities

Fallacies
* Powerful instruction은 높은 성능을 보장한다?
- 아니다. 연산은 최대한 간단하고 적어야 한다. CISC와 RISC를 생각해보자. 연산은 최대한 간단해야 한다.
* 집적 어셈블리 코드를 작성하는 것이 더 좋은 성능을 낼 수 있다?
- 20년 전에는 가능했다. 그때는 집적 인간이 어셈블리어를 작성하는 게 더 빨랐지만 이제는 컴파일러가 인간이 작성하는 것을 뛰어넘는다. 인간이 작성하는 어셈블리 코드에는 한계가 있으며 실수도 나타날 수 있다.
* 새로운 연산이 계속 생기는 중이다?
- 연산의 개수는 실제로 계속 늘어나고 있다. 그러나 이는 새로운 연산들이 생겨서 그런 것이 아니다. 예전에 사용했던 연산들을 사용하지 않아서이다. 연산은 최대한 적고 간단해야 한다. 따라서 새로운 연산들이 계속 생기는 것이 아니다.
챕터 2의 Design Principles를 요약하면 다음과 같다.
1.Simplicity favors regularity
2.Smaller is faster
3.Make the common case fast
4.Good design demands good compromises
Lecture Note #7에 계속..
'Lecture Note > Computer Architecture' 카테고리의 다른 글
| 컴퓨터 구조(CA) Lecture Note #8 (0) | 2020.10.13 |
|---|---|
| 컴퓨터 구조(CA) Lecture Note #7 (0) | 2020.10.05 |
| 컴퓨터 구조(CA) Lecture Note #5 (0) | 2020.09.26 |
| 컴퓨터 구조(CA) Lecture Note #4 (0) | 2020.09.19 |
| 컴퓨터 구조(CA) Lecture Note #3 (0) | 2020.09.12 |
- Total
- Today
- Yesterday
- BFS
- node.js
- 세그먼트 트리
- 시뮬레이션
- nest.js
- ReactNative
- 백준
- 그래프
- 백트래킹
- 투포인터
- 구현
- Computer Architecture
- 컴퓨터 통신
- 재귀
- dfs
- nestjs
- 컴퓨터 구조
- 중앙대학교
- 자바스크립트
- 그리디
- 동적계획법
- 예외처리
- boj
- 벨만포드
- 알고리즘
- nodeJS
- 자바
- java
- typeORM
- 스레드
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |