
티스토리 뷰
이 포스트는 「"Computer Organization and Design -The hardware / software interface"
by Patterson and Hennessy, 5th edition, 2013.」을 참고하여 작성했습니다.
Representing Instructions
명령들을 나타내는 방법에 대해 알아보자.
MIPS에서 명령들은 32Bit으로 Encoded 된다. 이는 ISA마다 다를 수 있다. MIPS는 32개의 레지스터를 가지고 있다.
레지스터들은 각각의 번호마다 쓰이는 역할이 다르다. (Green card 참조)
먼저 R-format 연산에 대해 살펴보자.

R-format은 위 그림과 같이 구성되어 있다.
op필드는 이 연산이 어떤 연산인지를 나타낸다. 만약 R-format의 연산이라면 추가적으로 funct비트를 확인한다.
rs와 rt필드는 레지스터의 소스를 나타낸다. 연산 후 rd에 저장된다.
rd는 destination 레지스터로 연산 결과가 저장된다.
shamt는 쉬프트 연산 시에 쓰인다.
funct는 op코드의 확장된 개념으로 해당 연산이 어떠한 연산인지를 나타낸다.
R-format의 연산에는 add, sub, and, or, slt연산이 있다.
rs, rt, rd의 비트가 각각 5비트인 이유는 총 32개의 레지스터를 표현하기 위함이다.
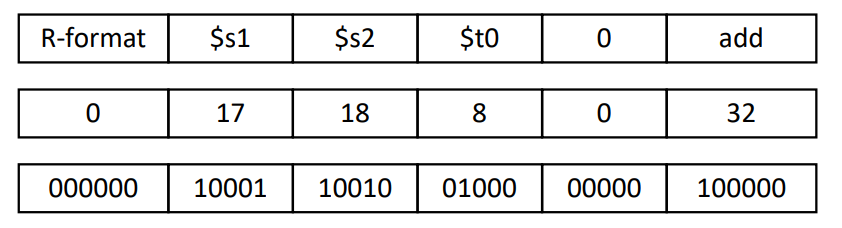
위 예시를 통하여 연산이 어떻게 저장되는지 알아보자.
먼저 op코드가 0이므로 해당 연산은 R-format이므로 funct비트를 확인해야 한다.
funct비트가 32이므로 해당 연산은 add연산임을 알 수 있다.
또한 rs, rt, rd필드는 해당 레지스터의 number를 나타낸다. 레지스터의 number마다 사용하는 방법이 다르다.
이렇게 하여 결국 아래에 binary 형태로 나타난 코드가 실제 컴퓨터가 이해하는 코드이다.
위 연산을 HEX코드로 표현하면 0x02324020이다.
다음은 I-format 연산에 대해 살펴보자.

I-format은 R-format과 달리 rd필드와 shamt필드가 없고 constant or adress를 저장하는 필드가 있다.
op코드는 어떠한 연산이건 반드시 필요하며 사용되는 연산에 따라 형태가 다를 수 있다.
마지막 constant or address필드에서는 주소를 저장하거나 immediate를 저장하여 상수 연산 및 lw, sw연산을 수행할 수 있다.
해당 포맷에서는 rt가 목적지 or 소스로 둘 다 사용되며, rs는 주소의 offset을 저장하고, 마지막 필드에서는 unsigned 2^16의 상수를 나타낼 수 있다.
R-format연산에는 lw, sw, beq, bne, slti, lui 등 자주 사용하는 연산들이 존재한다.
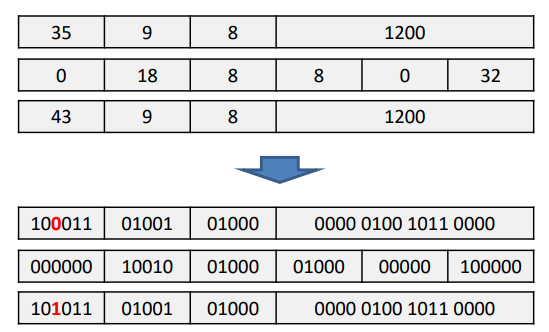
예를 들어 A [300]=h+A [300]이라는 C 코드를 MIPS코드로 컴파일하여 보자.
lw $t0, 1200($t1)
add $t0, $s2, $t0
sw $t0, 1200($t1)
과 같이 번역될 것이다. 각 연산들을 아래와 같이 나타낼 수 있다.
Logical Operations
논리 연산에 대해 알아보자.
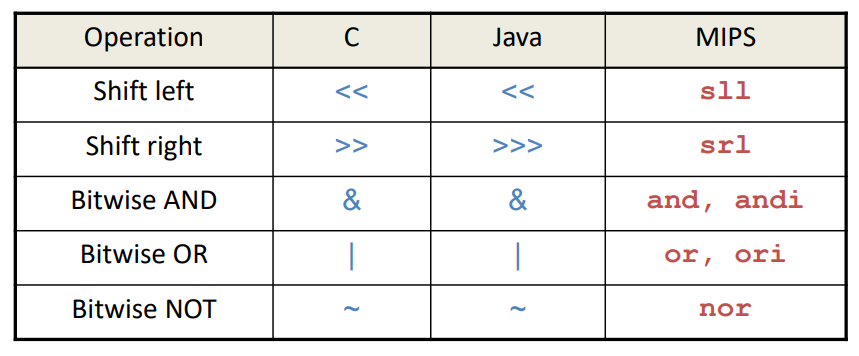
논리 연산의 종류는 위 그림과 같다. 이제 하나씩 알아보자.
먼저 시프트 연산에 대해 알아보자. 시프트 연산은 bit를 left, right로 원하는 값만큼 움직이는 연산이다.
예를 들어 $s0<<4라는 연산은 s0의 비트 값을 4만큼 왼쪽으로 밀어낸다. 예를 들어 1101 0011이라는 bit가 있다면
0011 0000이 될 것이다. >>는 똑같은 논리를 오른쪽으로 적용시켜주면 된다.
아까 위에서 살펴본 R-format에서의 shamt필드가 이때에 사용된다.
shamt필드는 몇 개의 bit이 shift 되었는지를 기록하는 필드이다.
left shift를 i번 반복한다면 해당 값에 2^i의 값을 곱한 결과와 같다. right shift를 i번 반복한다면 해당 값에 2^i를 나눠준 값과 같다(unsigned 한정) 따라서 2^i의 연산을 수행한다면 시프트 연산을 사용하는 것이 실행 속도가 훨씬 빠르다.
참고로 논리 연산과 산술 연산은 다른 점이 존재한다.
left연산에선 논리 연산이나 산술 연산이나 밀린 비트를 0으로 채우지만 right연산에선 산술 시프트 연산의 경우 sign비트가 확장된다. 즉 1001 0011을 >>2 하게 되면 1110 0100이 된다.
AND, OR연산은 생략
MIPS에서의 NOT연산을 살펴보자. NOT연산은 비트를 뒤집는 연산이다. 그러나 MIPS에는 NOT연산이 존재하지 않는다. 다만 NOR연산을 통해 NOT연산과 똑같은 기능을 수행할 수 있다.
NOR 연산이란 NOT과 OR연산을 합친 연산이라 생각하면 좋으며 a NOR b == NOT(a OR b)와 같다.
예를 들어 nor $t0, $t1, $zero 연산이 있을 때 이 연산은 t1 OR zero 된 값을 t0에 저장하는 연산이다.
알다시피 0과 OR연산을 하게 되면 아무런 변화도 일어나지 않는다. 따라서 위 연산은 NOT연산과 똑같은 기능을 하는 연산이 된다.
Stored Program Computers
프로그램은 연산들의 집합이다. 프로그램은 메모리에 저장되며 즉 연산들은 메모리에 저장되어 실행된다.
프로그램이 실행되는 과정은 프로그램에 있는 연산들이 실행되는 것이며 결국 메모리에 있는 연산들을 이곳저곳 이동하는 과정이라고 생각할 수 있다.
같은 ISA를 사용하여 번역된 머신 코드는 다른 CPU에서도 사용이 가능하다.
Conditional branch instruction인 beq연산과 bne연산에 대해 알아보자.
beq rs, rt, L1연산은 rs와 rt가 같다면 L1로 분기하는 연산이다.
bne rs, rt, L1연산은 rs와 rt가 다르다면 L1로 분기하는 연산이다.
만약 조건을 만족하지 않는다면 계속하여 다음 명령을 수행하게 된다.
Unconditional branch instruction에는 j연산이 있다.

위 C 코드를 MIPS코드로 번역하여 보자.
beq $s3, $s4, IF
sub $s0, $s1, $s2
j Exit
IF: add $s0, $s1, $s2
Exit :...
와 같이 번역할 수 있다. 똑같은 논리로 bne를 이용하여도 번역이 가능하다. 이는 컴파일러가 결정한다.


반복문 역시 bne 혹은 beq를 이용하여 다음과 같이 번역할 수 있다.
그 외에 추가적인 Conditional 연산에는 대소 비교를 해주는 slt과 slti연산이 존재한다.
slt rd, rs, rt 연산은 rs <rt일 경우에 rd에 1을 저장하며 그렇지 않으면 0을 저장한다.
즉 True : 1, False : 0의 값을 저장하게 된다.
slt연산과 beq, bne연산을 이용하여 우리는 모든 비교 연산을 만들 수 있다.(==,!=,>=,<= 등)
slt $t0, $s1, $s2
bne $t0, $zero, L
위 연산을 해석해보자. 먼저 s1과 s2의 크기를 비교하여 s1 <s2라면 t0에 1을 저장한다.
밑에 bne연산은 t0이 0이 아니라면, 즉 t0이 1이라면 L로 분기한다.
만약 t0에 1이 아닌 0이 저장되었다면 s1>=s2임을 알 수 있다.
slti연산은 I-foramt으로 상수 연산에 쓰인다.
또 slt에는 부호의 존재 유무에 따라 사용하는 연산이 다르다. signed의 경우 slt를 unsigned의 경우 sltu를 사용한다.
왜냐면 부호 비트를 사용하냐 안 하냐에 따라 값이 달라지게 되며, 해당 연산의 결과도 달라질 수 있기 때문이다.

=,!=연산은 >, <= 연산 등에 비해 실행 속도가 빠르다. 따라서 blt, bqe연산 같은 것은 존재하지 않는다. slt와 beq연산의 조합으로 구현이 가능하기 때문이다.
Procedure Calling
함수의 호출이 일어나는 과정을 연산의 관점에서 살펴보자.

과정을 위 그림과 같이 요약할 수 있다.
먼저 PC와 $ra의 개념을 알아야 한다.
PC란 Program Counter로 실행될 명령의 주소를 담고 있다.
ra란 함수의 return adress를 담고 있다.
프러시저 콜은 jal함수를 통해 이루어진다.
jal 은 jump-and-link로 먼저 다음 연산의 주소를 $ra에 저장하고, target의 주소로 이동하는 연산이다.
jr연산은 target의 레지스터로 이동하는 연산이다. $ra의 값을 PC에 넣어 프로시져 return이 이루어지게 한다.
다음의 예시를 살펴보자.
main함수에서는 foo() 함수를 부른다. foo() 함수에서는 bar() 함수를 부른다 위 과정을 이해해 보자.
먼저 main함수에서 foo() 함수가 등장하게 되면 jal foo연산을 수행하게 된다. 해당 연산은 $ra의 값에 PC+4의 값을 저장한 후에 foo함수로 이동하게 된다.
foo함수로 들어왔다. 현재의 $ra는 main함수에 foo함수 다음에 수행할 연산일 것이다.
foo함수에서 bar() 함수를 만났다. 이때 다시 jal bar연산을 수행하게 될 텐데 문제가 있다.
$ra의 값에는 이미 main함수에 존재하는 연산의 주소가 담겨있다. 만약 여기서 $ra연산을 쓰게 된다면 덮여 쓰기가 되어 main함수로 돌아갈 수 없을 것이다. 그러므로 우리는 Stack을 이용하여 이 문제를 해결한다(추후 다시 설명) Stack에 $ra의 값을 저장하고 bar함수로 이동한다.
bar함수로 들어왔다. 현재 $ra의 값은 foo함수에 존재하는 연산일 것이다. bar함수에서는 별다른 함수 call이 없으므로 해당 함수를 마무리하고 값을 return 하게 된다. 앞서 살펴봤지만 return에 사용되는 레지스터는 $v0,$v1이다.
bar함수를 return 하여 값을 전달하고 다시 foo함수로 돌아와 나머지 연산을 수행한다. foo함수가 끝나면 다시 main함수로 돌아가게 된다.
위 과정을 통해 확인했듯이 결국 프로그램이 실행되는 과정은 메모리 안에서 메모리 주소를 이곳저곳 이동하여 이루어지는 것임을 알 수 있다.
Register Usage and Stack
추가적인 레지스터와 스택에 대해 알아보자.
MIPS 레지스터에는 다음과 같은 레지스터가 존재한다.
$v0,$v1 : return값을 담는 레지스터이다. return값은 오직 하나만 존재한다. 따라서 하나의 레지스터만 필요하다.
그러나 레지스터가 두 개 존재하는 이유는 만약 리턴 값이 32bit을 넘을 경우 $v1을 이용하여 추가적인 공간을 사용한다.
$a0-$a3 : argument를 저장하는 레지스터이다. 오직 4개만 존재하며 만약 4개가 넘을 시 메모리의 stack을 이용한다.
$t0-$9 : temporaries값을 저장하는 레지스터이다. 이 레지스터의 값들은 다른 함수 호출 시 보존되지 않는다. 덮여 쓰일 수 있는 값이다.
$s0-$s7 : saved값을 저장하는 레지스터이다. 이 레지스터 값들은 보존되어야 하는 값이므로 메모리의 stack을 이용하여 미리 값을 복사해놓고 덮어쓴 다음 return 하기 전에 원래의 값을 restore 한다.
$gp : global pointer 글로벌 변수에 쓰인다.
$sp : stack pointer
$fp : frame pointer
$ra : return adress
가 존재한다.
다음은 Stack에 대해 알아보자. 레지스터가 한정적인 개수만 존재하므로 우리는 Stack을 이용한다.
LIFO구조이며 스택 포인터인 $sp를 통하여 가장 최근에 할당된 주소를 가리킨다.
스택의 주소는 최신에 할당될수록 낮아진다.

스택은 위 그림과 같은 구조를 갖고 있다.
함수가 호출되면 현재 Stack의 Pointer에 +를 하여 해당 공간을 사용하게 된다. 함수가 하나 실행될 때마다 가운데에 있는 그림과 같은 Stack의 덩어리가 생성된다고 생각하면 된다. 각 공간은 argument, return adress, saved 레지스터 등을 저장하고 있다.

이 C 코드는 다음과 같은 MIPS코드로 번역될 수 있다.

과정을 살펴보겠다.
먼저 addi연산을 통해 스택 포인터를 -4 감소시켜 4바이트만큼의 Stack사용 공간을 확보하고 sw를 이용하여 $s0의 값을 현재 스택의 위치에 저장한다.
그 후 (g+h) - (i+j)를 수행하기 위한 덧셈과 뺄셈 연산을 수행한 후에 우리는 return 값인 $v0에 해당 결과를 저장한다.
이때 add연산을 사용한 것을 볼 수 있는데 MIPS에는 별도의 COPY연산이 존재하지 않고 ADD연산과 ZERO를 이용하여 COPY의 역할을 수행한다.
그 후 처음에 스택에 저장해놓았던 값을 $s0에 불러온 후 (여기선 사용 x) 스택 포인터를 다시 4를 더하여 사용했던 스택 공간을 없애(?) 준다. 그 후 저장되어있는 $ra를 이용하여 본래의 함수로 리턴한다. 이때 $v0에는 리턴 값이 담겨있다.
다음은 재귀 함수에서의 호출 과정을 살펴보자.

위와 같은 C언어로 작성된 Factorial을 계산하는 코드가 있다.

과정을 살펴보자.
처음에 addi를 통하여 8만큼의 Stack사용 공간을 확보했다. 왜냐면 재귀적으로 함수를 수행하기 위해서는 $ra와 argument인 $a 0가 덮여 쓰여서는 안 되기 때문이다.
따라서 해당 스택에 $ra와 $a0의 값을 저장한 다음 if연산을 수행한다.
만약 if(n <1)을 만족한다면 분기가 일어나지 않고 아래에 있는 addi연산을 수행하게 되며 만약 조건을 만족하지 않는다면 아래 L1 구문으로 이동하게 된다.
해당 구문에서는 $a0의 값을 -1만큼 감소하여 다시 한번 함수를 호출하게 된다.
새롭게 호출된 함수는 다시 Stack을 할당하고 현재 argument와 $ra를 저장한 후에 위와 똑같은 작업을 수행한다.
그렇게 하여 만약 argument가 0이 된다면 이제 더 이상 재귀가 일어나지 않고 return이 시작될 것이다.
먼저 스택의 Top에 위치한 함수는 사용했던 stack주소를 +해줌으로 스택을 pop 하여 $ra로 이동한다.
이렇게 하여 이동된 주소는 jal fact 밑인 lw명령일 것이다. 즉 함수가 리턴되어 돌아왔으므로 현재 함수의 Stack에서 $a0와 $ra를 다시 load 하여 리턴 주소와 현재 함수의 argument를 불러와 이전 함수에서 리턴 받았던 $v0과 곱하는 연산을 수행한 후에 다시 $ra주소로 리턴한다. 이 과정을 첫 함수가 불려졌던 곳까지 반복할 것이며 결국 사용했던 모든 Stack이 pop 되고 마지막에 남은 $v0이 팩토리얼의 결과값이 될 것이다.
Memory Layout
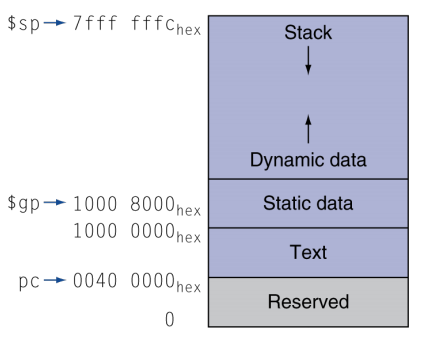
메모리는 위 그림과 같은 구조를 가지고 있다.
Text : Program code
Static data : 전역 변수
Dynamic data : heap(malloc,new)
Stack : automatic storage
Dynamic data영역은 점점 높은 주소로, Stack은 점섬 낮은주소로 할당 된다.
만약 Stack과 Dynamic data영역이 만나게 된다면 더 이상 메모리를 새로운 곳에 사용할 수 없다.
만약 메모리 Protection이 있다면 프로그램이 Crash되겠지만 Protection이 없다면 동적 데이터와 스택이 만나더라도 아무일도 일어나지않아 데이터를 덮어쓰게 되어 프로그램에 치명적 오류를 발생시킬 수 있다.
Reserved영역은 특별한 사용을 위해 예약되어 있는 공간이다.
Lecture Note #6에서 계속..
'Lecture Note > Computer Architecture' 카테고리의 다른 글
| 컴퓨터 구조(CA) Lecture Note #7 (0) | 2020.10.05 |
|---|---|
| 컴퓨터 구조(CA) Lecture Note #6 (0) | 2020.09.28 |
| 컴퓨터 구조(CA) Lecture Note #4 (0) | 2020.09.19 |
| 컴퓨터 구조(CA) Lecture Note #3 (0) | 2020.09.12 |
| 컴퓨터 구조(CA) Lecture Note #2 (0) | 2020.09.12 |
- Total
- Today
- Yesterday
- 구현
- 알고리즘
- 재귀
- 세그먼트 트리
- nestjs
- node.js
- 투포인터
- 동적계획법
- 백준
- BFS
- nodeJS
- 중앙대학교
- 스레드
- 벨만포드
- 시뮬레이션
- 예외처리
- 자바스크립트
- 그래프
- 컴퓨터 구조
- dfs
- nest.js
- 그리디
- 컴퓨터 통신
- ReactNative
- Computer Architecture
- 백트래킹
- 자바
- java
- boj
- typeORM
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |